Einführung in NodeJs
Aktualisiert am September 24, 2024 Lesedauer: 11 Minuten
Einführung
Wenn Sie versuchen, etwas über das Web zu lernen
Bei der Entwicklung stellen wir normalerweise fest, dass das Front-End wesentlich zugänglicher ist als das Back-End. Dafür gibt es viele Gründe, insbesondere das Gefühl eines sofortigen Feedbacks, das entsteht, wenn man ein bestimmtes Element einer Seite im Code ändert und bemerkt, dass die Änderung auf die Website angewendet wird. Für Anfänger ist dieses Feedback oft hilfreich, da es ihnen ermöglicht, ihren Code anzupassen und aus ihren Fehlern zu lernen. Leider ist dies beim Backend nicht der Fall: Oftmals wird viel Arbeit darauf verwendet, die Umgebung im Voraus einzurichten und die erforderlichen Abhängigkeiten zu installieren, damit eine einfache „Hallo Welt“-Meldung auf dem Terminal angezeigt wird. Glücklicherweise In der Open-Source-Community werden ständig große Fortschritte bei der Erleichterung des Entwicklungsprozesses von Frameworks erzielt, und die Verbesserung der Entwicklererfahrung ist ein gutes Beispiel dafür. Dieses Framework ist eine sehr leistungsfähige Technologie, die das Schreiben serverseitig ermöglicht Code in Javascript ist praktisch und bietet eine Vielzahl integrierter Tools und Funktionen, die es von seinen Mitbewerbern unterscheiden. In diesem Artikel werden wir NodeJs und sein Ökosystem mit einem praktischen Ansatz erkunden und ein voll funktionsfähiges Projekt erstellen.
Was werden wir bauen?
ToDo-Anwendungen sind ein Projekt der Wahl für Anfänger, die die Front-End-Entwicklung erlernen. Aus diesem Grund haben wir uns entschieden, eine Todo-Listen-API zu erstellen. Dadurch können wir unserer Schnittstelle Datenpersistenz hinzufügen und diese Daten bearbeiten (durch Hinzufügen, Aktualisieren, Löschen von Aufgaben usw.).
Den endgültigen Code finden Sie hier.
Unsere Werkzeuge
Wir werden für dieses Projekt einen vereinfachten Tech-Stack verwenden. Es kann als Minimalversion vieler Tools betrachtet werden, die Sie in realen Projekten finden, da die übergeordneten Ideen dieselben sind. Die Details der Implementierung und die Wahl eines bestimmten Tools gegenüber einem anderen sind für den Anfang nicht wichtig.
– NodeJs ist, wie bereits erwähnt, eines der beliebtesten Javascript-Frameworks zum Erstellen serverseitiger Anwendungen.
-
ExpressJs ist ein minimales Javascript-Framework, das auf NodeJS basiert. Es beschleunigt den Entwicklungsprozess durch die Verwendung vieler integrierter Funktionen. Es wird auch als Möglichkeit zur Standardisierung der Entwicklungspraktiken in NodeJS-Projekten verwendet, um die Verwendung für Ingenieure zu erleichtern.
-
LowDB ist eine einfache In-Memory-Datenbank. Dank seiner Einfachheit können wir zeigen, wie man in einem NodeJs-Projekt mit einer Datenbank interagiert, ohne sich mit fortgeschritteneren Themen wie Bereitstellungen und Konfigurationen befassen zu müssen.
Nachdem wir nun alle Tools identifiziert haben, die wir verwenden werden, greifen wir zu unseren Tastaturen und beginnen mit dem Codieren!
Installation
Node ist auf allen Plattformen verfügbar. Alle Installationsanleitungen finden Sie auf der offiziellen Website. Windows-Benutzer sollten darauf achten, den Knoten Pfad zu Umgebungsvariablen hinzuzufügen, damit er in der Befehlszeile verwendet werden kann.
Außerdem muss npm installiert sein. Npm ist der Standard-Paketmanager für NodeJs. Dadurch können wir unsere Projektabhängigkeiten verwalten. Die Installationsanleitung finden Sie hier.
Projektinitialisierung
Gehen Sie zum Link und klonen Sie das Starterprojekt:
Dies ist ein einfaches Starter-Repository für unser Projekt. Es enthält alle Abhängigkeiten, die wir zusammen mit der Projektdateistruktur verwenden werden. Wir werden jedes Element erklären, sobald wir es erreicht haben. Öffnen Sie Ihr Terminal, navigieren Sie zum Pfad des Projekts und führen Sie den Befehl aus:
npm install
Dadurch werden alle Abhängigkeiten des in der Datei package.json angegebenen Projekts installiert. package.json ist die Datei im Stammverzeichnis jedes Javascript/NodeJs-Projekts. Sie enthält Metadaten zu letzterem und wird zur Verwaltung aller Projektabhängigkeiten, Skripte und Versionen verwendet.
Nachdem alle Abhängigkeiten installiert sind, können wir unsere Anwendung starten:
npm run start
„start“ ist ein Skript, das wir im Paket angegeben haben. json-Datei. Es gibt die Eintragsdatei für unsere Anwendung an, in unserem Fall app.js.
Die folgende Meldung sollte nun in Ihrem Terminal erscheinen:

Das bedeutet, dass unser Server erfolgreich gestartet ist und auf alle an Port 3000 gesendeten Anfragen wartet. Schauen wir uns app.js an und erklären, was hier passiert:

App.js ist unsere Projekteintragsdatei (und derzeit die einzige). Wir instanziieren eine Express-Anwendung mit dem Namen app, geben an, dass alle Anfragen mit der http-Methode „GET“ und dem Unterpfad „/“ über diese Route verarbeitet werden, übergeben eine Funktion namens Middleware, die das Anfrage- und Antwortobjekt als aufnimmt Parameter. Dies ist von entscheidender Bedeutung, da die Anfrage alle für ihre Bearbeitung erforderlichen Informationen enthält (Parameter, Anfragetext, Anfrageheader usw.) und das Antwortobjekt dasjenige ist, das an den Client zurückgegeben wird. Wir beginnen damit, dass wir einfach die Nachricht „Hallo Welt“ senden. Danach lassen wir unsere Anwendung alle eingehenden Anfragen an den angegebenen Port (in unserem Fall 3000) abhören und protokollieren die Meldung „Listening to port 3000“, um anzuzeigen, dass unsere Anwendung betriebsbereit und bereit ist, Anfragen zu empfangen.
Öffnen Sie Ihr Terminal, geben Sie in der Linkleiste „localhost:3000/“ ein und drücken Sie die Eingabetaste. Dies ist der angegebene Pfad, über den wir unseren Server lokal erreichen können. Sie erhalten folgende Meldung:

Datenbankkonfiguration
Lowdb ist eine Open-Source-Datenbank, die einfach zu verwenden ist und keine spezielle Einrichtung erfordert. Die Grundidee dahinter besteht darin, alle Daten in einer lokalen JSON-Datei zu speichern. Nachdem LowDB installiert ist (was geschehen ist, als wir alle Abhängigkeiten installiert haben), können wir den folgenden Code zu db.js hinzufügen:

Dieser Code ist dem in der offiziellen Dokumentation von LowDB enthaltenen Code sehr ähnlich. Wir haben es für unseren eigenen Anwendungsfall ein wenig optimiert. Erklären wir es Zeile für Zeile:
Die ersten paar Zeilen dienen dem Import der notwendigen Abhängigkeiten. „join“ ist eine Dienstprogrammfunktion, die im Modul „path“ verfügbar ist. Es ist eines der Kernmodule von NodeJs, das viele Methoden für den Umgang mit Pfaden bietet. „Low“ und „JSONFile“ sind die beiden von LowDB bereitgestellten Klassen. Der erste erstellt die JSON-Dateiinstanz, die unsere Daten enthalten wird. Der zweite erstellt die eigentliche Datenbankinstanz, die darauf reagieren wird. Schließlich ist „lodash“ eine der am häufigsten verwendeten Javascript-Bibliotheken, die eine Vielzahl von Hilfsfunktionen für allgemeine Programmieraufgaben bietet. Wir fügen es unserer Datenbankinstanz hinzu, damit wir seine erweiterten Methoden zur Verarbeitung unserer Daten nutzen können.
Zuerst geben wir den Pfad für die db.json-Datei an. Es ist die Datei, die unsere Daten enthält und an LowDB übergeben wird. Wenn die Datei im angegebenen Pfad nicht gefunden wird, erstellt LowDB eine.
Anschließend übergeben wir den Dateipfad an den LowDB-Adapter und übergeben ihn an unsere neue LowDB-Datenbankinstanz. Die Variable „db“ kann dann zur Kommunikation mit unserer Datenbank verwendet werden. Sobald die Datenbankinstanz erstellt ist, lesen wir mithilfe von db.read() aus der JSON-Datei. Dadurch wird das Feld „Daten“ in unserer Datenbankinstanz festgelegt, sodass wir auf den Datenbankinhalt zugreifen können. Beachten Sie, dass wir dieser Zeile „await“ vorangestellt haben. Damit soll angegeben werden, dass die Auflösung dieser Anweisung möglicherweise eine unbekannte Zeitspanne in Anspruch nimmt und dass der NodeJs-Prozess auf seine Ausführung warten muss, bevor er mit dem Rest des Codes fortfährt. Wir tun dies, weil für den Lesevorgang Speicherzugriff auf die angegebene Datei erforderlich ist und die Zeit zur Ausführung dieser Art von Vorgang von den Spezifikationen Ihres Computers abhängt.
Nachdem wir nun Zugriff auf das Datenfeld haben, legen wir es als Objekt fest, das ein leeres Array von Beiträgen enthält. Oder besser gesagt: Wir prüfen, ob die Datei vorherige Daten enthält, und legen das leere Array fest, wenn dies nicht der Fall ist.
Schließlich führen wir db.write() aus, um die von uns vorgenommenen Änderungen an den Daten anzuwenden, und exportieren die Datenbankinstanz, damit sie in anderen Dateien in unserem Projekt verwendet werden kann.
Allgemeiner Anfrage-/Antwort-Workflow
Betrachten Sie das folgende Diagramm:

Es zeigt die allgemeine Architektur, die in einer Vielzahl von Backend-Anwendungen angewendet wird, die mit NodeJs/Express erstellt wurden. Wenn Sie den allgemeinen Arbeitsablauf hinter der Bearbeitung einer Anfrage verstehen, können Sie nicht nur NodeJs-Anwendungen erstellen und strukturieren, sondern diese Konzepte auch in praktisch jeden technischen Stack Ihrer Wahl übertragen. Wir werden die verschiedenen Ebenen untersuchen, die diesen Prozess stören, und ihre Rollen erklären:
## HTTP-Anfrageschicht
Dies ist die erste Ebene unserer Anwendung. Stellen Sie sich das als Gateway vor, das eine Vielzahl unterschiedlicher Anfragen von verschiedenen Clients empfängt. Jede Anfrage wird dann analysiert und zur Bearbeitung an den dafür vorgesehenen Teil der Anwendung weitergeleitet.
-
Router: Hier beziehen wir uns auf Express-Router, aber dieses Konzept ist in vielen Backend-Frameworks zu finden. Router sind eine Möglichkeit, die logische Verteilung in unserer Geschäftslogik auf unseren Code anzuwenden, was bedeutet, dass jeder Satz von Elementen, die ähnliche Funktionen gemeinsam haben, von demselben Eintrag verarbeitet wird und vom Rest der Sätze getrennt werden kann. Dies hat den Vorteil, dass jede Komponente des Codes unabhängig von den anderen ist und einfacher zu warten und zu erweitern ist. Genauer gesagt und als Beispiel werden alle Anfragen, die die Bedingungen des gemeinsam genutzten URL-Pfads „/posts“ erfüllen, vom selben Router verarbeitet. Abhängig von ihrer http-Methode (GET, POST usw.) wird ein anderer Controller verwendet.
-
Controller: Ein Controller empfängt gefilterte Anfragen von Routern, wendet zusätzliche Verarbeitung an und ruft die geeigneten Dienstmethoden auf.
Geschäftslogikschicht
Diese Ebene ist je nach den spezifischen Anwendungsfällen der Anwendung und der dahinter stehenden Geschäftslogik einzigartig.
-
Dienste: Dienste sind eine Reihe von Methoden, die die Kernlogik der Anwendung enthalten. Sie interagieren auch mit der Datenbank durch die Verwendung von ORMs/ODMs.
-
Dienste von Drittanbietern: Viele moderne Anwendungen entscheiden sich dafür, einen Teil der Anwendungslogik an dedizierte Dienste zu delegieren, auf die über eine API zugegriffen werden kann. Dienste dieser Art können Zahlungsabwicklungsdienste, statische Dateispeicherung, Benachrichtigungen und andere sein.
-
ODM/ORM: ORMs und ODMs fungieren als Vermittler zwischen den Diensten und der Datenbank. Ihre Aufgabe besteht darin, eine Abstraktion auf hoher Ebene für eine Datenbank bereitzustellen, die es einem Entwickler ermöglicht, Code in der Programmiersprache seiner Wahl zu schreiben, anstatt in dedizierten Datenbanksprachen wie SQL.
Datenpersistenzschicht
- Datenbanken: Wie bereits erwähnt, benötigen fast alle Anwendungen eine Form der Datenpersistenz. Dieser Teil wird von Datenbanken übernommen, und abhängig von der Art der Daten, der Geschäftslogik und vielen anderen Überlegungen wird die Wahl einer bestimmten Datenbank gegenüber einer anderen als entscheidend für die Effizienz und Skalierbarkeit der Anwendung angesehen.
Beispiel: Einen Beitrag hinzufügen
Nachdem wir nun die allgemeine Idee hinter der Architektur verstanden haben, wenden wir sie auf unser einfaches Beispiel an. Wir werden die Funktion zum Hinzufügen eines Todo-Beitrags zu unserer Anwendung implementieren. Nehmen wir an, dass jeder Beitrag eine eindeutige ID hat, die es uns ermöglicht, ihn später in unserer Datenbank zu identifizieren, einen Titel, der eine Zeichenfolge ist, und eine Reihenfolge, die vom Typ Ganzzahl ist. Nach unserem Diagramm beginnen wir mit der Implementierung des Routers. Fügen Sie der Datei index.js den folgenden Code hinzu:
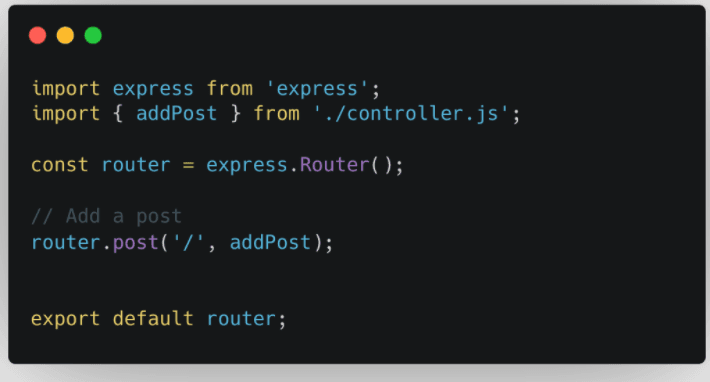
Dies ist unsere Router-Datei. Wir importieren Express und die „addPost“-Methode von unserem Controller (diese werden wir in Kürze implementieren), erstellen eine Instanz des Express-Routers und binden die addPost-Methode an unseren Router – das heißt, für jede Anfrage, die den Root-Pfad und das http hat Methode „POST“ wird die Methode „addPost“ aufgerufen, um damit umzugehen.
Bevor wir unsere Methode im Controller implementieren, verweisen wir in unserer Hauptdatei app.js auf den neuen Router und geben seinen Pfad als „/posts“ an: Alle Routen mit den angegebenen Pfaden werden an diesen Router weitergeleitet, damit er verarbeitet werden kann durch die verschiedenen Controller-Methoden:

Wir importieren den Router und nennen ihn „Beiträge“. app.use(“/posts”,..) bedeutet, dass alle Anfragen mit dem Unterpfad „/posts“, unabhängig von ihrer http-Methode, an den angegebenen Router weitergeleitet werden.
Weitere Änderungen an app.js umfassen den Import der Datenbankkonfigurationsdatei, damit sie ausgeführt werden kann, und die Verwendung von express.json() als Middleware, um uns den Zugriff auf das Anforderungstextobjekt zu ermöglichen.
Nachdem wir nun unsere Routen festgelegt haben, können wir die Methode „addPost“ in der Datei „controller.js“ hinzufügen:

„addPost“ ist eine Middleware-Funktion, die als Parameter die Anforderungs-, Antwortobjekte und die nächste Funktion verwendet. Wenn die nächste Funktion aufgerufen wird, wechselt der Prozess zur nächsten Middleware in der Kette oder beendet die Anforderung. Im Code der Methode extrahieren wir den Titel und die Reihenfolge aus dem Anfragetext und übergeben diese als Parameter an die Servicefunktion „createPost“. Diese Funktion übernimmt die Beitragsattribute, erstellt einen neuen Beitrag und gibt ihn zurück. Sobald der neue Beitrag erstellt wurde, senden wir ihn zusammen mit dem Statuscode 200 an den Kunden zurück, was bedeutet, dass die Anfrage erfolgreich war. Möglicherweise stellen Sie fest, dass unser Code in einen Try/Catch-Block eingefügt ist, um unerwartete Fehler abzufangen und an die nächste Middleware weiterzuleiten. Es gilt als bewährte Vorgehensweise, an alle Router eine Fehlerbehandlungs-Middleware anzuschließen, die den Fehler extrahiert und eine aussagekräftige Fehlermeldung an den Client zurückgibt.
Jetzt müssen Sie nur noch die Funktion „createPost“ in service.js implementieren:

Wie wir bereits bei der Erläuterung der verschiedenen Schichten der Architektur erwähnt haben, interagiert die Serviceschicht mit der Datenspeicherlösung über ORM/ODM. In unserem Beispiel müssen wir jedoch kein separates ORM verwenden, da Lowdb über eine integrierte Unterstützung für Javascript verfügt. Alle Details zur Syntax finden Sie in der Dokumentation.
Die Methode „createPost“ erhält Titel und Reihenfolge als Parameter und erstellt daraus das Post-Objekt. Für die eindeutige ID verwenden wir eine spezielle Bibliothek namens „Nanoid“, die eine eindeutige Zeichenfolge generiert. Wir fügen den neuen Beitrag zum Posts-Array in der Datenbank hinzu und schreiben diese Änderungen; Der neue Beitrag wird dann von der Funktion zurückgegeben.
Da „createPost“ nun bereit ist, ist die Funktion zum Hinzufügen von Beiträgen nun abgeschlossen und betriebsbereit. Wir testen es mit Postman, einem beliebten Tool zum Testen von APIs:

Wir wählen „POST“ als http-Methode für die Anfrage zusammen mit dem angegebenen URL-Pfad „localhost:3000/posts“. Wir fügen den Titel und die Reihenfolge als JSON-Format im Textbereich hinzu und senden die Anfrage. Wie oben gezeigt, erhalten wir zusammen mit dem neu erstellten Beitrag den Status 200 OK.
Abschluss
In diesem Projekt wurden viele Konzepte und Ideen untersucht: Wir behandelten die Installation und Einrichtung unserer Projektumgebung, lernten, wie man LowDB für die lokale Datenpersistenz konfiguriert, erkundeten die allgemeine Architektur von NodeJS/Express-Backend-Anwendungen und sahen, wie das geht Wenden Sie es in einem einfachen Beispiel an. Abschließend haben wir unsere Anwendung mit Postman getestet.
Die Absicht hier war, eine vereinfachte Version all dessen darzustellen, was zur Erstellung moderner Backend-Anwendungen gehört. Wie wir bereits gesehen haben, ist NodeJs ein leistungsstarkes Tool, mit dem wir einfache und komplexe APIs erstellen können. In Kombination mit seinem umfangreichen Ökosystem an Frameworks wie Express und einer Vielzahl von Tools und Bibliotheken für nahezu jeden Anwendungsfall ist es eine legitime Lösung für die moderne Backend-Entwicklung – eine Lösung, die wir zum Erlernen und Beherrschen empfehlen.