Introduction à NodeJs
Mis à jour le September 24, 2024 Temps de lecture : 13 min
Introduction
Lorsque vous essayez d'en apprendre davantage sur le Web
développement, nous constatons généralement que le front-end est nettement plus accessible que le back-end. Il y a de nombreuses raisons à cela, notamment le sentiment de retour instantané qui résulte de la modification d'un certain élément d'une page dans le code et de la remarque du changement appliqué au site Web. Ces retours sont souvent utiles aux débutants, car ils leur permettent d'ajuster leur code et d'apprendre de leurs erreurs. Malheureusement, ce n'est pas le cas avec le backend : souvent, une quantité importante de travail est consacrée à la configuration initiale de l'environnement et à l'installation des dépendances nécessaires pour qu'un simple message « Hello World » apparaisse sur le terminal., de nombreux progrès sont constamment réalisés dans la communauté open source pour faciliter le processus de développement des frameworks, et l'amélioration de l'expérience du développeur en est un bon exemple. Ce framework est une technologie très performante qui permet d'écrire côté serveur. code en Javascript pratique et offre une variété d'outils et de fonctionnalités intégrés qui le différencient de ses concurrents. Dans cet article, nous explorerons NodeJs et son écosystème, avec une approche pratique, en construisant un projet entièrement fonctionnel.
Qu'allons-nous construire ?
Les applications ToDo sont un projet incontournable pour les débutants qui apprennent le développement front-end. C'est pourquoi nous avons décidé de créer une API de liste Todo. Cela nous permettra d'ajouter de la persistance des données à notre interface, et nous donnera la possibilité de manipuler ces données (en ajoutant, mettant à jour, supprimant des tâches, etc….).
Le code final peut être trouvé ici.
Nos outils
Nous utiliserons une pile technologique simplifiée pour ce projet. Il peut être considéré comme une version minimale de nombreux outils que vous trouverez dans des projets réels, la raison étant que les idées de niveau supérieur sont les mêmes. Les détails de mise en œuvre et le choix d’un outil spécifique plutôt qu’un autre ne sont pas importants pour commencer.
-
NodeJs, comme nous l'avons mentionné, est l'un des frameworks Javascript les plus populaires pour créer des applications côté serveur.
-
ExpressJs est un framework Javascript minimal utilisé sur NodeJS. Il accélère le processus de développement en utilisant de nombreuses fonctionnalités intégrées. Il est également utilisé comme moyen de standardiser les pratiques de développement dans les projets NodeJS afin de faciliter son utilisation par les ingénieurs.
-
LowDB est une simple base de données en mémoire. Sa simplicité nous permet de montrer comment interagir avec une base de données dans un projet NodeJs, sans aborder des sujets plus avancés comme les déploiements et les configurations.
Maintenant que nous avons identifié tous les outils que nous allons utiliser, passons à nos claviers et commençons à coder !
##Installation
Node est disponible sur toutes les plateformes. Tous les guides d'installation sont disponibles sur le site officiel. Les utilisateurs Windows doivent s'assurer d'ajouter le nœud chemin d'accès aux variables d'environnement afin qu'il puisse être utilisé sur la ligne de commande.
Nous aurons également besoin d’installer npm. Npm est le gestionnaire de packages standard pour NodeJs. Cela nous permettra de gérer les dépendances de nos projets. Le guide d'installation peut être trouvé ici.
Initialisation du projet
Rendez-vous sur le lien et clonez le projet de démarrage :
Il s'agit d'un simple référentiel de démarrage pour notre projet. Il contient toutes les dépendances que nous utiliserons ainsi que la structure des fichiers du projet. Nous expliquerons chaque élément une fois atteint. Ouvrez votre terminal, accédez au chemin du projet et exécutez la commande :
npm install
Cela installera toutes les dépendances du projet spécifié dans le fichier package.json. package.json est le fichier trouvé à la racine de tout projet Javascript/NodeJs, il contient des métadonnées sur ce dernier et est utilisé pour gérer toutes les dépendances, scripts et versions du projet.
Une fois toutes les dépendances installées, nous pouvons démarrer notre application :
npm run start
« start » est un script que nous avons spécifié dans le package. fichier json. Il spécifie le fichier d'entrée de notre application, qui dans notre cas est app.js.
Le message suivant devrait maintenant apparaître dans votre terminal :

Cela signifie que notre serveur a démarré avec succès et écoute toutes les requêtes envoyées au port 3000. Regardons app.js et expliquons ce qui se passe ici :

App.js est notre fichier d'entrée de projet (et le seul à ce stade). Nous instancions une application express nommée app, spécifions que toutes les requêtes qui ont la méthode http « GET » et le sous-chemin « / » seront traitées par cette route, transmettons une fonction appelée middleware, qui prend en charge l'objet de requête et de réponse comme paramètres. Ceci est crucial, car la requête contient toutes les informations nécessaires à son traitement (paramètres, corps de la requête, en-têtes de la requête, etc.), et l'objet de réponse est celui qui sera renvoyé au client. Nous commençons par simplement envoyer le message « Bonjour tout le monde ». Après cela, nous faisons en sorte que notre application écoute toutes les demandes entrantes sur le port spécifié (dans notre cas, 3000) et enregistrons le message « Écoute du port 3000 » pour indiquer que notre application est opérationnelle et prête à recevoir des demandes.
Ouvrez votre terminal et dans la barre de liens, tapez « localhost:3000/ », puis appuyez sur Entrée. Il s'agit du chemin spécifié que nous pouvons utiliser pour atteindre notre serveur localement. Vous recevrez le message suivant :

Configuration de la base de données
Lowdb est une base de données open source facile à utiliser et ne nécessite aucune configuration spécifique. L'idée générale est de stocker toutes les données dans un fichier json local. Une fois LowDB installé (ce qui a été fait lorsque nous avons installé toutes les dépendances), nous pouvons ajouter le code suivant à db.js :

Ce code est assez similaire à celui trouvé dans la documentation officielle de LowDB. Nous l'avons légèrement modifié pour notre propre cas d'utilisation. Expliquons-le ligne par ligne :
Les premières lignes servent à importer les dépendances nécessaires. « join » est une fonction utilitaire disponible dans le module « path ». C'est l'un des modules de base de NodeJs qui offre de nombreuses méthodes pour traiter et gérer les chemins. « Low » et « JSONFile » sont les deux classes exposées par LowDB. Le premier crée l'instance de fichier json qui contiendra nos données. Le second crée l'instance de base de données réelle qui agira sur elle. Enfin, « lodash » est l'une des bibliothèques javascript les plus utilisées offrant une grande variété de fonctions utilitaires pour les tâches de programmation courantes. Nous l'ajoutons à notre instance de base de données pour nous permettre d'utiliser ses méthodes avancées pour gérer nos données.
Tout d’abord, nous spécifions le chemin du fichier db.json. C'est le fichier qui contiendra nos données, et sera transmis à LowDB. Si le fichier n'est pas trouvé au chemin spécifié, LowDB en créera un.
Nous transmettons ensuite le chemin du fichier à l'adaptateur LowDB et le transmettons à notre nouvelle instance de base de données LowDB. La variable « db » peut alors être utilisée pour communiquer avec notre base de données. Une fois l'instance de base de données créée, nous lisons le fichier json en utilisant db.read(). Cela définira le champ « données » dans notre instance de base de données afin que nous puissions accéder au contenu de la base de données. Notez que nous avons précédé cette ligne par « attendre ». Il s'agit de préciser que cette instruction peut prendre un temps inconnu à résoudre, et que le processus NodeJs doit attendre son exécution avant de procéder au reste du code. Nous faisons cela parce que l'opération de lecture nécessite un accès mémoire au fichier spécifié, et le temps d'exécution de ce type d'opération dépend des spécifications de votre machine.
Maintenant que nous avons accès au champ de données, nous le définissons comme un objet contenant un tableau vide de publications, ou plutôt, nous vérifions si le fichier contient des données antérieures et définissons le tableau vide si ce n'est pas le cas.
Enfin, nous exécutons db.write() pour appliquer les modifications que nous avons apportées aux données et exportons l'instance de base de données afin qu'elle puisse être utilisée dans d'autres fichiers de notre projet.
Workflow général de demande/réponse
Considérons le schéma suivant :

Il montre l'architecture générale appliquée dans une pléthore d'applications backend construites avec NodeJs/Express. Comprendre le flux de travail général derrière le traitement d'une demande vous permettra non seulement de créer et de structurer des applications NodeJs, mais vous permettra également de transférer ces concepts dans pratiquement n'importe quelle pile technique de votre choix. Nous explorerons les différentes couches qui interfèrent avec ce processus et expliquerons leurs rôles :
## Couche de requête HTTP
Il s'agit de la première couche de notre application, imaginez-la comme une passerelle qui reçoit un large éventail de requêtes différentes provenant de différents clients, chaque requête est ensuite analysée et transmise à la partie dédiée de l'application pour qu'elle soit traitée.
-
Routeurs : nous faisons ici référence aux routeurs Express, mais ce concept se retrouve dans de nombreux frameworks backend. Les routeurs sont un moyen d'appliquer la distribution logique de notre logique métier à notre code, ce qui signifie que chaque ensemble d'éléments partageant des fonctionnalités similaires est géré par la même entrée et peut être séparé du reste des ensembles. Cela présente l’avantage de rendre chaque composant du code indépendant des autres et plus facile à maintenir et à étendre. Plus précisément, et à titre d'exemple, toutes les requêtes qui remplissent les conditions du chemin d'URL partagé « /posts » seront traitées par le même routeur. En fonction de leur méthode http (GET, POST, etc.), un contrôleur différent sera utilisé.
-
Contrôleurs : un contrôleur reçoit les requêtes filtrées des routeurs, applique un traitement supplémentaire et appelle les méthodes de service appropriées.
Couche de logique métier
Cette couche est unique en fonction des cas d'utilisation spécifiques de l'application et de la logique métier qui la sous-tend.
-
Services : les services sont un ensemble de méthodes qui contiennent la logique de base de l'application. Ils interagissent également avec la base de données via l'utilisation de ORM/ODM.).
-
Services tiers : de nombreuses applications modernes choisissent de déléguer une partie de la logique de l'application à des services dédiés accessibles via une API. Les services de ce type peuvent être des services de gestion des paiements, de stockage de fichiers statiques, de notifications, etc.
-
ODM/ORM : les ORM et les ODM jouent le rôle d'intermédiaires entre les services et la base de données. Leur rôle est de fournir une abstraction de haut niveau sur une base de données qui permet à un développeur d'écrire du code dans le langage de programmation de son choix au lieu de langages de base de données dédiés, tels que SQL.
Couche de persistance des données
- Bases de données : comme nous l'avons mentionné précédemment, presque toutes les applications nécessitent une certaine forme de persistance des données. Cette partie est gérée par les bases de données, et en fonction de la nature des données, de la logique métier et de nombreuses autres considérations, le choix d'une certaine base de données plutôt qu'une autre est considéré comme crucial pour l'efficacité et l'évolutivité de l'application.
Exemple : Ajouter une publication
Maintenant que nous comprenons l’idée générale derrière l’architecture, appliquons-la à notre exemple simple. Nous allons implémenter la fonctionnalité d'ajout d'une publication todo à notre application. Supposons que toute publication possède un identifiant unique qui nous permettra de l'identifier ultérieurement dans notre base de données, un titre qui est une chaîne et un ordre qui est de type entier. En suivant notre schéma, nous commencerons par implémenter le routeur. Ajoutez le code suivant au fichier index.js :
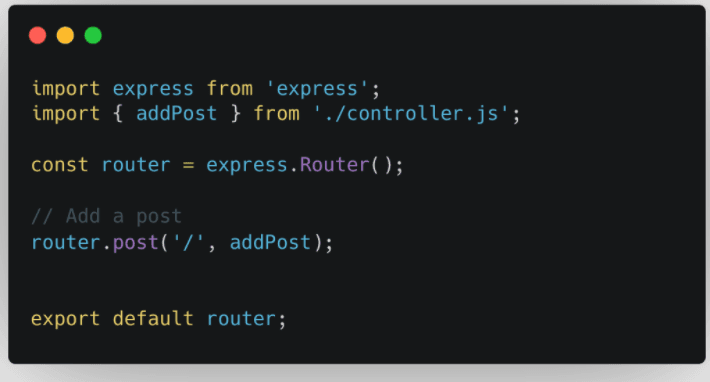
Ceci est notre fichier de routeur. Nous importons express et la méthode « addPost » depuis notre contrôleur (nous implémenterons celle-ci sous peu), créons une instance de routeur express et lions la méthode addPost à notre routeur - ce qui signifie que pour chaque requête qui a le chemin racine et le http méthode « POST », la méthode « addPost » sera appelée pour le gérer.
Avant d'implémenter notre méthode dans le contrôleur, nous référençons le nouveau routeur dans notre fichier app.js principal et spécifions son chemin comme « /posts » : toutes les routes avec les chemins spécifiés seront transmises à ce routeur, afin qu'il puisse être géré. par les différentes méthodes du contrôleur :

Nous importons le routeur et le nommons « posts ». app.use("/posts",..) signifie que toutes les requêtes avec le sous-chemin "/posts", quelle que soit leur méthode http, seront acheminées vers le routeur spécifié.
D'autres modifications apportées à app.js incluent l'importation du fichier de configuration de la base de données afin qu'il soit exécuté et l'utilisation de express.json() comme middleware pour nous permettre d'accéder à l'objet du corps de la requête.
Maintenant que nos routes sont définies, nous pouvons ajouter la méthode « addPost » dans le fichier controller.js :

« addPost » est une fonction middleware qui prend comme paramètres la requête, les objets de réponse et la fonction suivante. Lorsque la fonction suivante est appelée, le processus passe au middleware suivant de la chaîne ou met fin à la requête. Dans le code de la méthode, nous extrayons le titre et la commande du corps de la requête et les transmettons comme paramètres à la fonction de service « createPost ». Cette fonction prend les attributs de la publication, crée une nouvelle publication et la renvoie. Une fois la nouvelle publication créée, nous la renvoyons au client avec le code de statut 200, ce qui signifie que la demande a abouti. Vous remarquerez peut-être que notre code est placé dans un bloc try/catch afin de détecter toute erreur inattendue et de la transmettre au middleware suivant. Il est considéré comme une bonne pratique d'attacher à tous les routeurs un middleware de gestion des erreurs qui extrait l'erreur et renvoie un message d'erreur significatif au client.
Il ne reste plus qu'à implémenter la fonction « createPost » dans service.js :

Comme nous l'avons mentionné précédemment en expliquant les différentes couches de l'architecture, la couche de service interagit avec la solution de stockage de données via l'utilisation d'ORM/ODM. Cependant, dans notre exemple, nous n'aurons pas besoin d'utiliser un ORM distinct, puisque Lowdb est livré avec un support intégré pour Javascript. Tous les détails sur sa syntaxe peuvent être trouvés dans la documentation.
La méthode « createPost » reçoit le titre et l'ordre comme paramètres et les utilise pour créer l'objet de publication. Pour l'identifiant unique, nous utilisons une bibliothèque dédiée appelée « nanoid », qui génère une séquence unique de caractères. Nous ajoutons la nouvelle publication dans le tableau posts de la base de données et écrivons ces modifications ; le nouveau message est ensuite renvoyé par la fonction.
Maintenant que « createPost » est prêt, la fonctionnalité d’ajout de publications est désormais terminée et opérationnelle. Nous le testons à l'aide de Postman, un outil populaire pour tester les API :

Nous sélectionnons « POST » comme méthode http pour la requête avec le chemin URL spécifié « localhost:3000/posts ». Nous ajoutons le titre et la commande au format json dans la section corps et envoyons la demande. Comme indiqué ci-dessus, nous recevons le statut 200 OK avec le message nouvellement créé.
Conclusion
De nombreux concepts et idées ont été explorés dans ce projet : nous avons expliqué comment installer et configurer notre environnement de projet, appris à configurer LowDB pour la persistance des données locales, exploré l'architecture générale des applications backend NodeJS/Express et vu comment appliquez-le dans un exemple simple. Enfin, nous avons testé notre application avec Postman.
L'intention ici était d'exposer une version simplifiée de tout ce qui entre dans la création d'applications backend modernes. Comme nous l'avons vu précédemment, NodeJs est un outil puissant qui nous permet de créer des API simples et complexes. Combiné avec son riche écosystème de frameworks, tels qu'express et une pléthore d'outils et de bibliothèques pour à peu près tous les cas d'utilisation, il s'agit d'une solution légitime pour le développement backend moderne - une solution que nous recommandons d'apprendre et de maîtriser.