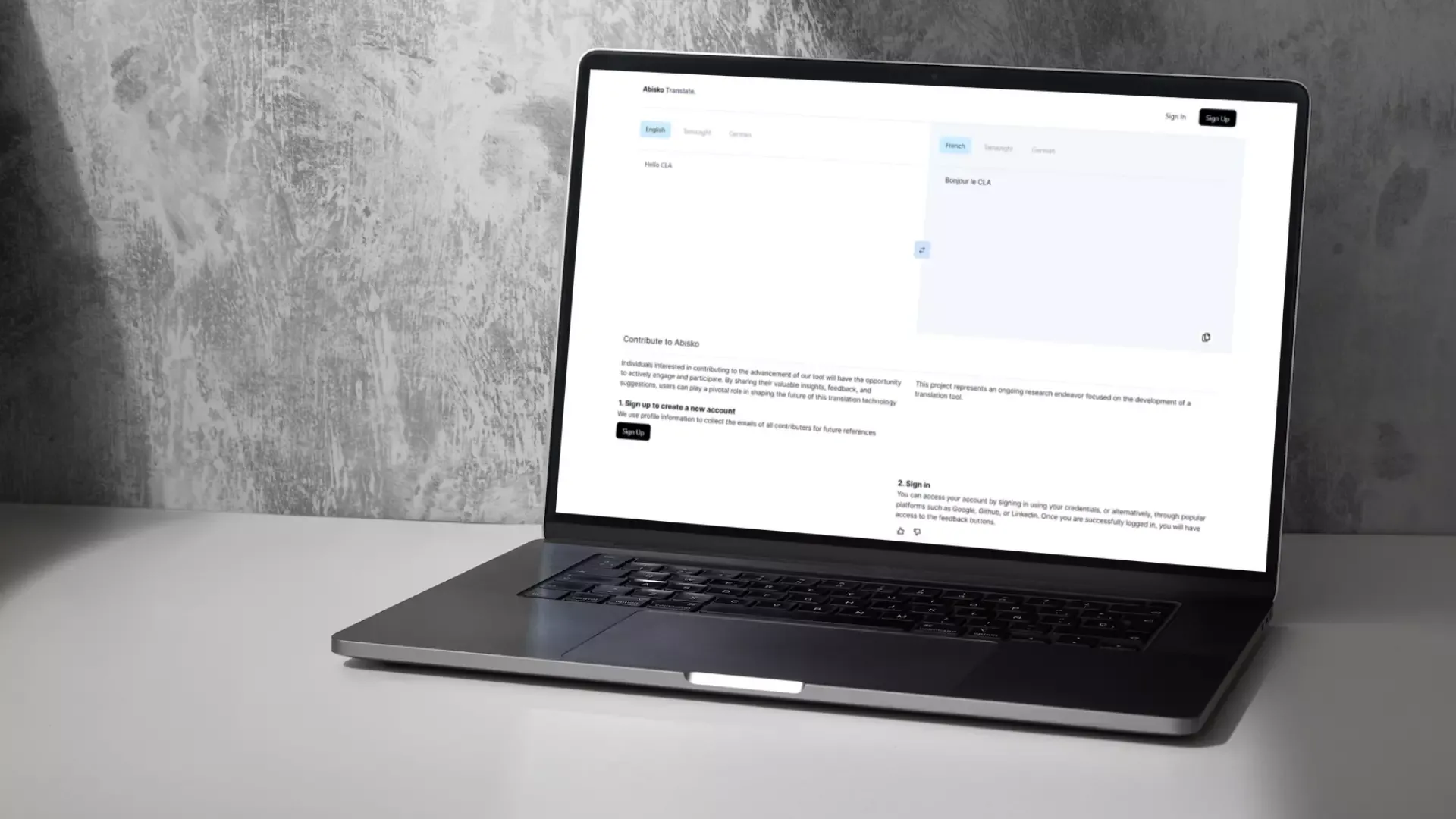
Blogera itzuli Sekuentziatik Sekuentziarako Itzulpen Automatikoaren Eredua Eguneratua September 24, 2024 4 Irakurri minutuak